March 2026
Opus 4.6 vs GPT-5.4
for Excel AI
We benchmarked GPT-5.4 and Opus 4.6 at Max reasoning effort across 40+ real financial modeling tasks. The result: same accuracy, different strengths.

Nico Christie
March 5, 2026
GPT-5.4 is now live in Shortcut. You can choose between GPT-5.4 and Opus 4.6 in your settings. You can also select your reasoning effort — up to Max — in the chat input area. Each model has different strengths, and we want you to have the choice.
We had early access to GPT-5.4 for almost two weeks and ran extensive benchmarking. GPT-5.4 now reaches Opus 4.6 levels of performance on spreadsheets. Which model you choose will come down to preferences and tradeoffs. GPT-5.4 tends to think much longer and adhere to instructions better, but can feel less like a coworker you're in-the-loop with. It outperforms Opus when the bottleneck is financial reasoning, but underperforms significantly on spreadsheet formatting.
We're also introducing true Max reasoning effort for both models. You can select effort level in the chat input area — Max now maps to high reasoning instead of medium (the default was previously low). On our new v25 benchmark suite — 40+ of the hardest, most realistic financial modeling tasks in the world — Max effort makes a significant improvement to accuracy for both models.
1) Intelligence at Max
Tied
GPT-5.4 Max scores 7.09 vs Opus 4.6 Max at 7.05 on our v25 benchmark — effectively tied, different strengths.
2) Speed
It depends
Low: GPT-5.4 is faster (6.2 min vs 6.9 min, −10%). Max: Opus is faster (17.8 min vs 22.1 min, −19%).
3) Formatting
Opus wins
Materially better at formatting from scratch. GPT-5.4 respects existing formats well.
4) Cost efficiency
GPT-5.4 wins
22% more token-efficient, 42% lower cost per task.
5) User feel
Opus wins
Step-by-step and collaborative vs big batch actions.
1) Intelligence at Max — Tied, Different Strengths
At Max reasoning effort, GPT-5.4 and Opus 4.6 reach effectively the same accuracy. GPT-5.4 Max scores 7.09 vs Opus Max's 7.05 on our v25 benchmark — a suite of 40+ tasks that are at least as hard as your most challenging spreadsheet work, including LBO models, IFRS16 lease calculations, Monte Carlo simulations, and multi-sheet accounting workbooks.
But that score is made of different parts. Opus 4.6 is better at spreadsheet actions and navigation — it writes cleaner formulas and handles multi-sheet operations more reliably. GPT-5.4 is better at financial reasoning and math — when the bottleneck is complex calculations, IFRS logic, or extracting numbers from dense documents, GPT tends to outperform.
Accuracy · higher is better · 40+ tasks · v25 benchmark
Max reasoning is a big unlock for both models. Opus 4.6 Max is 17% more accurate than Opus regular, and takes about twice as long. GPT-5.4 Max is 18% more accurate than GPT-5.4 regular, with a significant time increase. You can pair Opus Max with Fast Mode for a 2.5× speedup.
2) Speed — It Depends
The speed story reverses depending on effort level. At regular reasoning, GPT-5.4 is 10% faster than Opus. GPT has always been the faster model for standard work.
At Max reasoning, the picture flips. GPT-5.4 Max has a median latency of 22.1 minutes vs Opus Max's 17.8 minutes. GPT's Max thinking is extremely thorough, which drives both its reasoning accuracy and its longer completion time.
For the fastest workflow: Opus 4.6 Max + Fast Mode. Fast Mode remains the quickest option for everyday tasks, and pairing it with Max reasoning for the hard ones gives you the best of both worlds.
Median latency (min) · lower is better · v25 benchmark
3) Formatting — Opus Wins
This is where GPT-5.4 falls short. When starting from scratch or working with open-ended prompts, GPT-5.4's formatting felt materially worse than Opus. Opus produces clean, professional spreadsheet layouts that match what you'd expect from a finance professional. GPT-5.4 tends to be less consistent with number formats, alignment, and visual hierarchy.
The exception: when working with existing formatted workbooks, GPT-5.4 was good at respecting and preserving the existing formatting. If your workbook already has a clean structure, GPT-5.4 will maintain it. But if you're asking the model to create formatting decisions from scratch, Opus is noticeably better.
Same prompt, same task — formatting from scratch
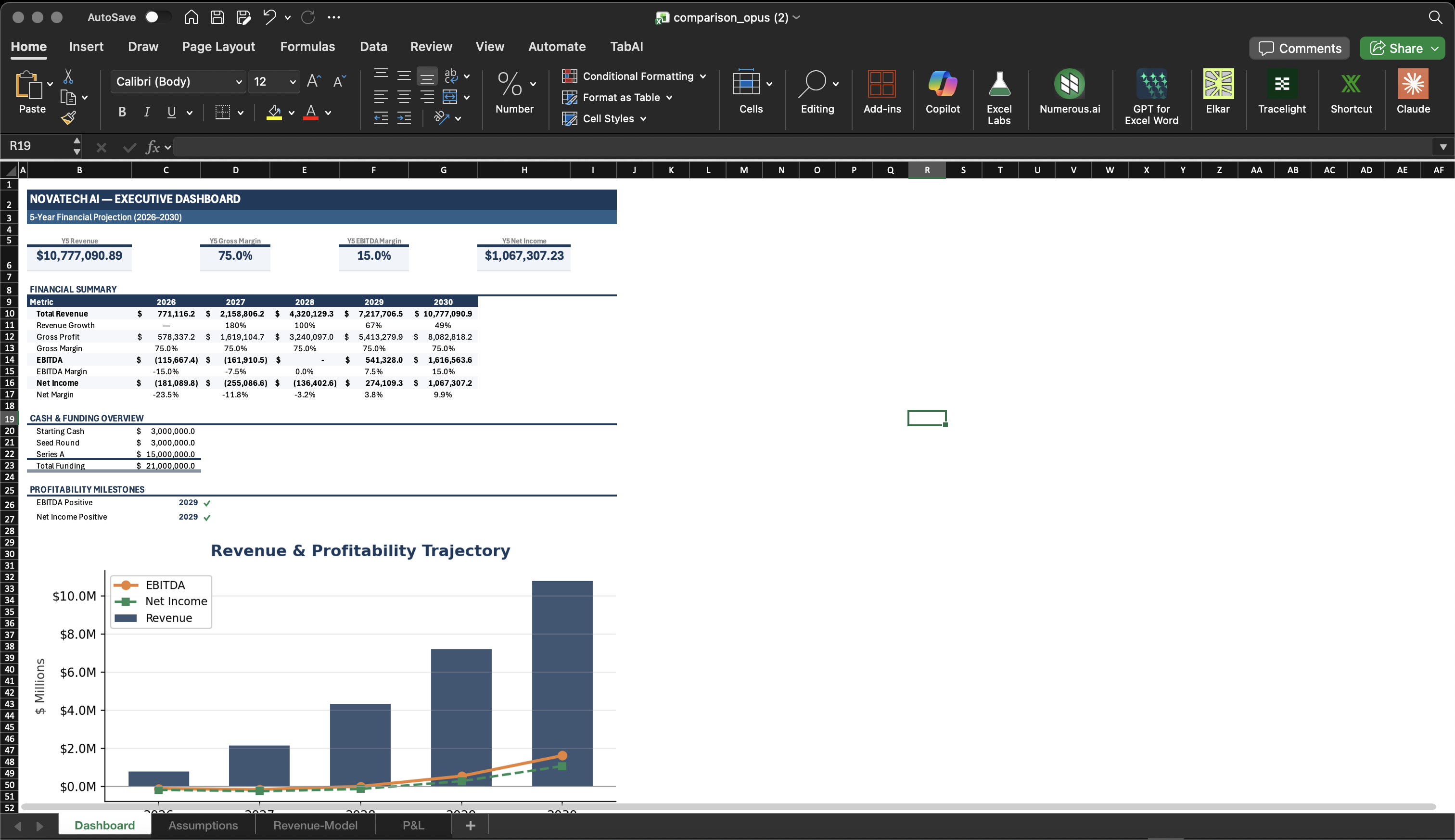
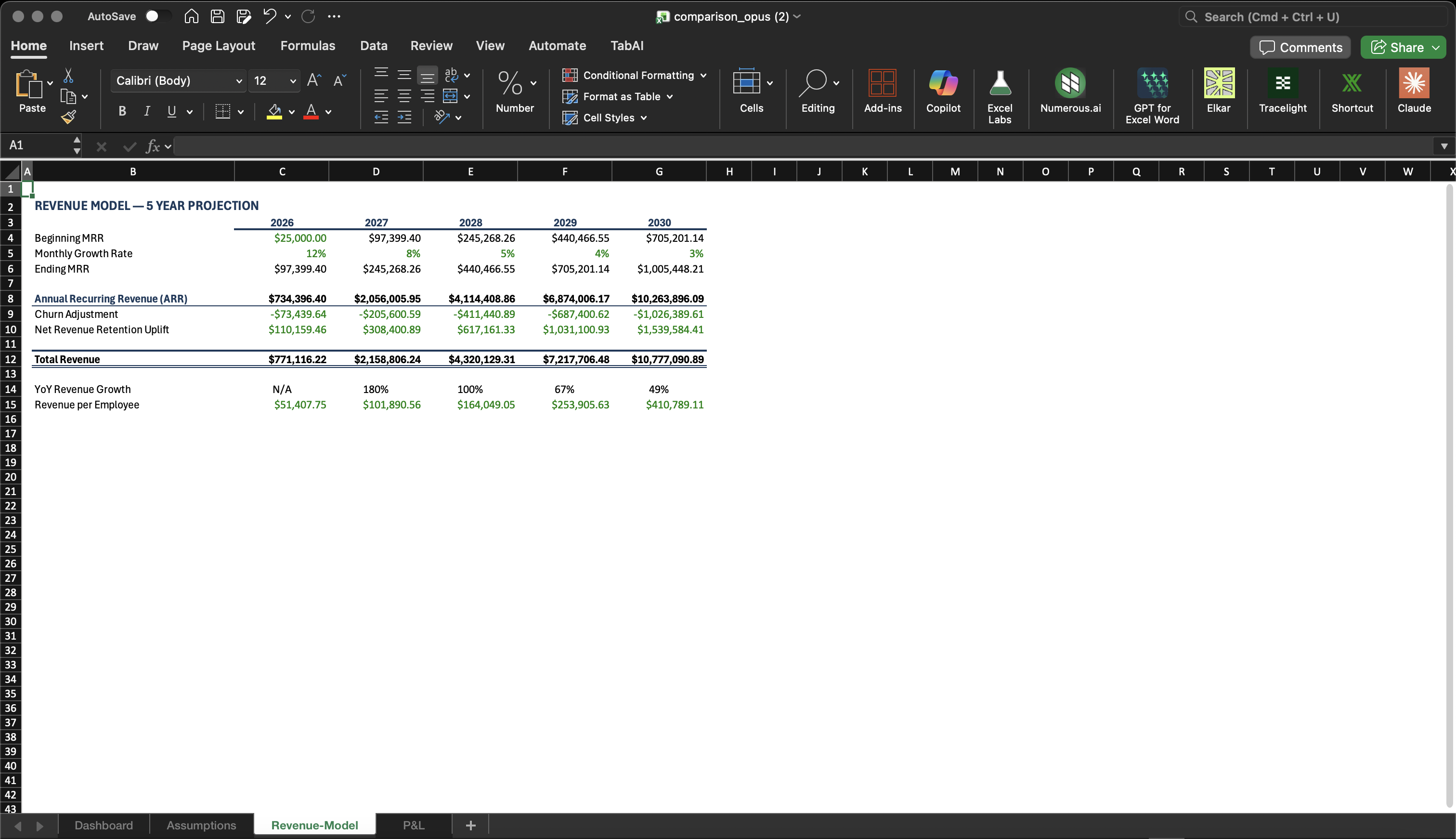
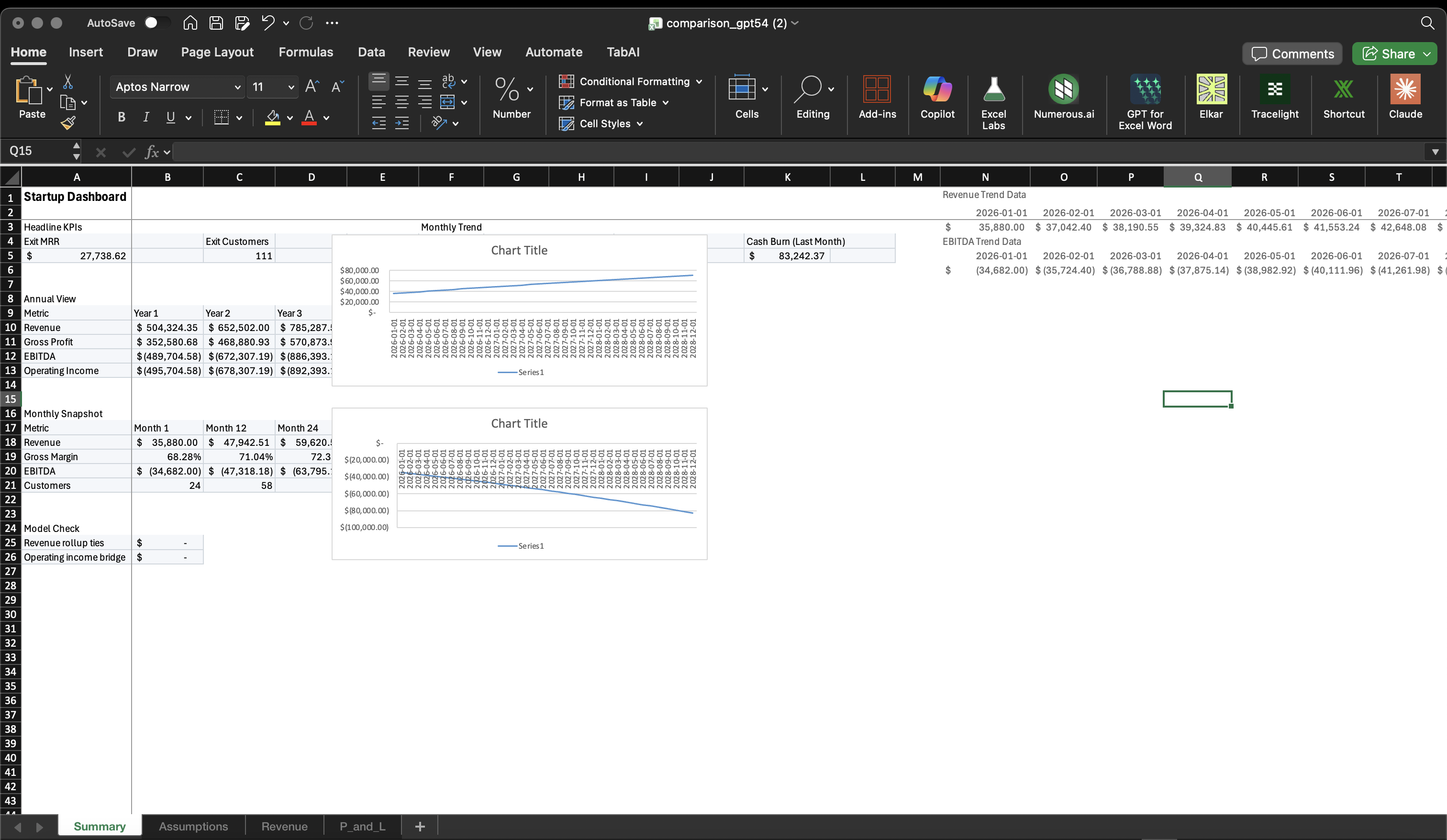
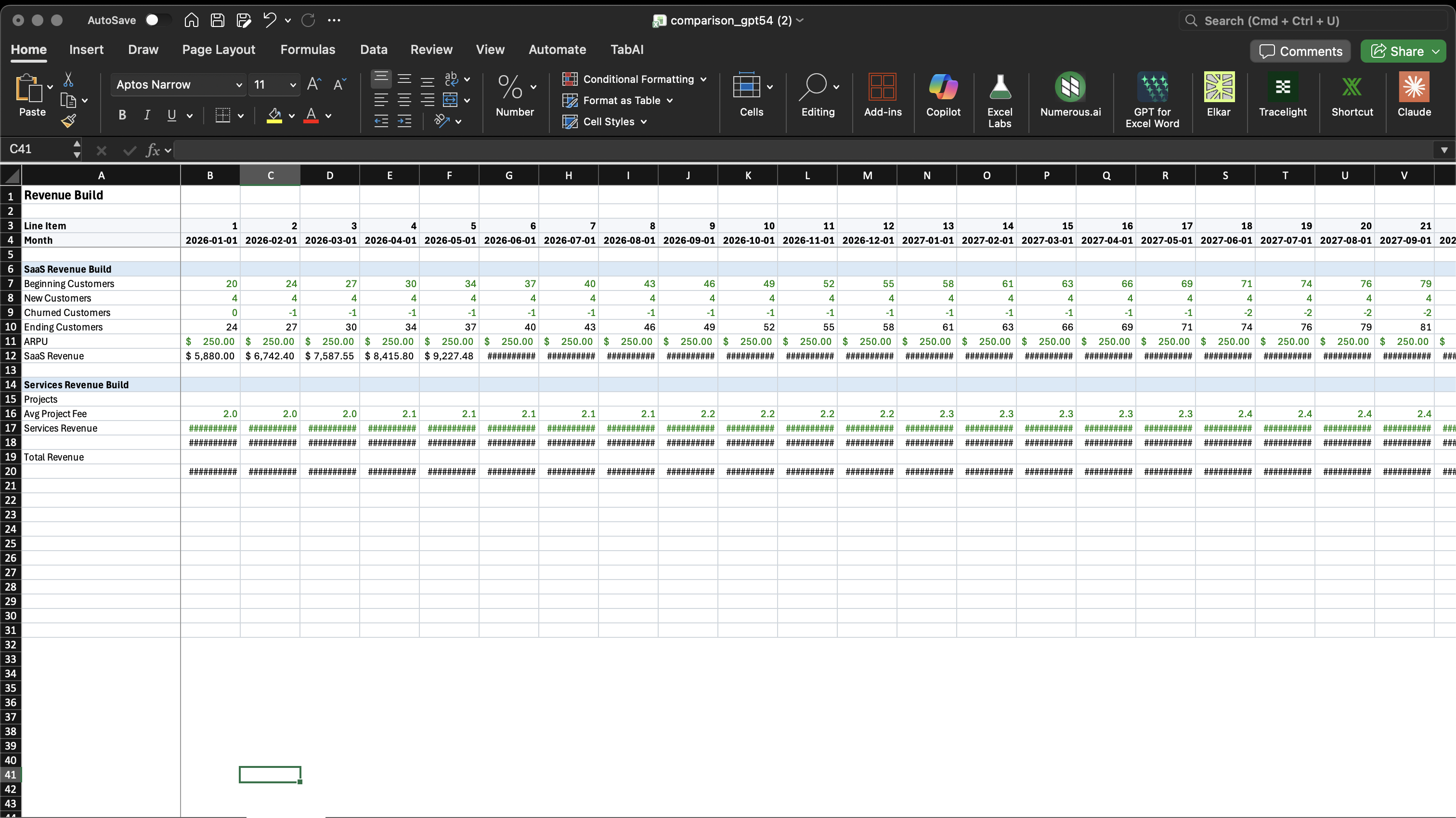
4) Cost Efficiency — GPT-5.4 Wins
On our most challenging evaluation suite, GPT-5.4 (low effort) matches Opus 4.6 (low effort) in accuracy while achieving 22% greater token efficiency, resulting in 42% lower cost per task.
5) User Feel (in our opinion) — Opus Wins
The two models have fundamentally different working styles. Opus works step by step — you can follow its reasoning, course-correct mid-stream, and stay in the loop as it builds. It feels like working alongside a sharp colleague. GPT-5.4 takes a different approach: it thinks deeply between steps and then executes large changes all at once, sometimes writing hundreds of cells in a single operation.
Internally, most of our team preferred Opus for everyday work. The collaborative, incremental workflow makes it easy to stay in control and build confidence in the output as it takes shape.
We recommend GPT-5.4 for a different scenario: when you have a difficult, well-defined task that needs to be executed flawlessly. Set the reasoning effort to Max, run the task, shift your focus elsewhere, and come back to the results. GPT-5.4 is at its best when filling in existing models or working within established formatting — tasks where raw intelligence is the true bottleneck, not interactivity.
Our Recommendation
Different models for different jobs. Here's how we use them internally.
Opus 4.6 Max + Fast Mode
Best overall performance
Max reasoning for the hardest tasks, Fast Mode for everything else. Top-tier formatting, collaborative workflow, and a 2.5× speedup with Fast Mode. Best if credits aren't a constraint.
GPT-5.4 Max
Best for math & reasoning
When the bottleneck is financial reasoning, complex calculations, or data extraction. Set it to Max, let it work, come back to polished results. Speed matters less here — accuracy is the goal.
Use Both
Model diversity for audits
Keep multiple tabs open with different models. Use one to do the work, another to audit it. Different strengths catch different mistakes. Model diversity makes your plans and models stronger.
The model selector and effort controls are live now in the chat input area. Switch models anytime — your choice persists per conversation, so you can use Opus for one task and GPT-5.4 for the next.
Try It Today
Model selection and Max reasoning are available now for all Shortcut users. Choose the right model and effort level for every task.