Introducing Pivot 0.5: A fast and powerful finance and spreadsheet model
We believe an applied research lab must have the capacity to train its own frontier models to control its destiny. Today, we’re introducing a research preview of our first model – Pivot 0.5.
A 27B model on the efficient frontier
Accuracy vs. blended price per task — Pivot 0.5 matches Sonnet 4.5 at ~3.5× lower cost.
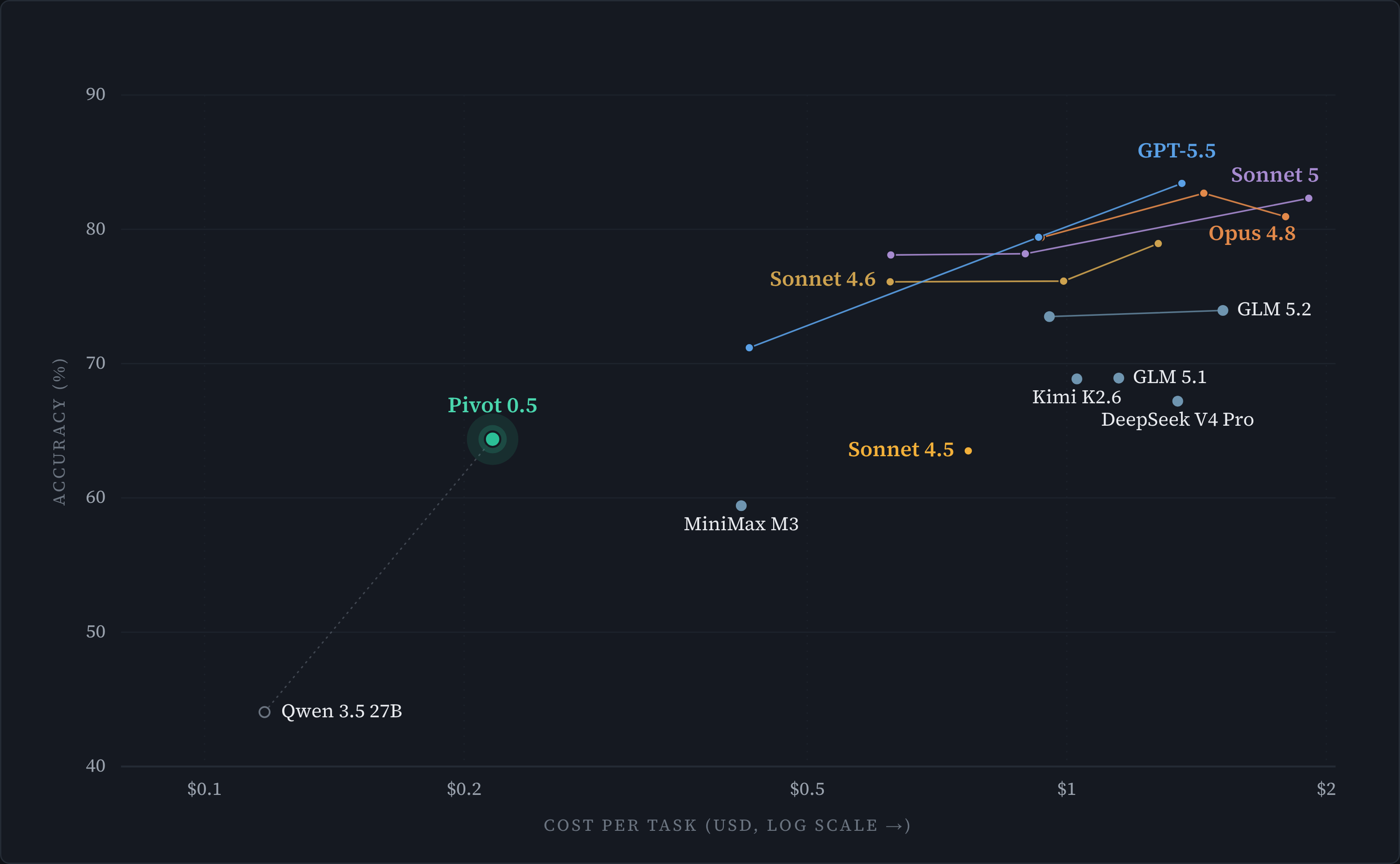
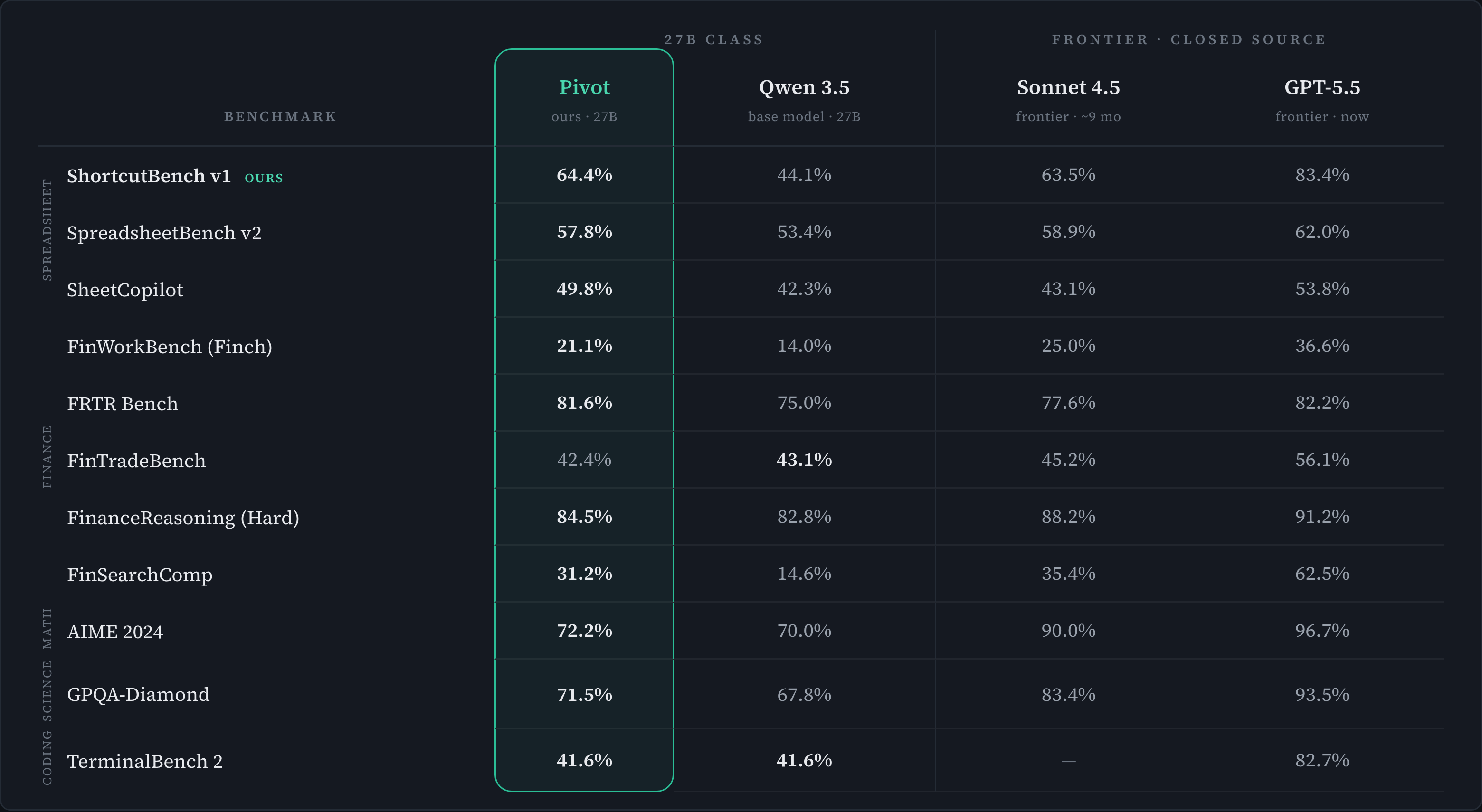
We built Pivot by post-training Qwen3.5-27B to perform well on long-horizon agentic tasks. On ShortcutBench v1, our Spreadsheet Agent benchmark (soon to be released), our training raised the score from 44% to 64.4%. Pivot also beats the base model on 7 out of 8 key public finance and spreadsheet benchmarks.
Pivot across public benchmarks
One agent harness, model swapped. Bold marks where Pivot beats its Qwen 3.5 base — Sonnet 4.5 & GPT-5.5 shown for reference.
Pivot’s 64.4% score closes in on large frontier open-weight models like DeepSeek v4 Pro (67.2%) and surpasses frontier close-source models as of 9 months ago (Sonnet 4.5). Compared to DeepSeek v4 Pro, it is 7x cheaper* per task ($0.2 vs $1.4 per task) and 40% faster (15.8min vs 26.9min per task).
Training Pivot
We trained Pivot entirely in-house and even built a new spreadsheet environment for RL along the way. Below, we’ll briefly walk through core parts of our training stack, starting with the dataset and recipe.
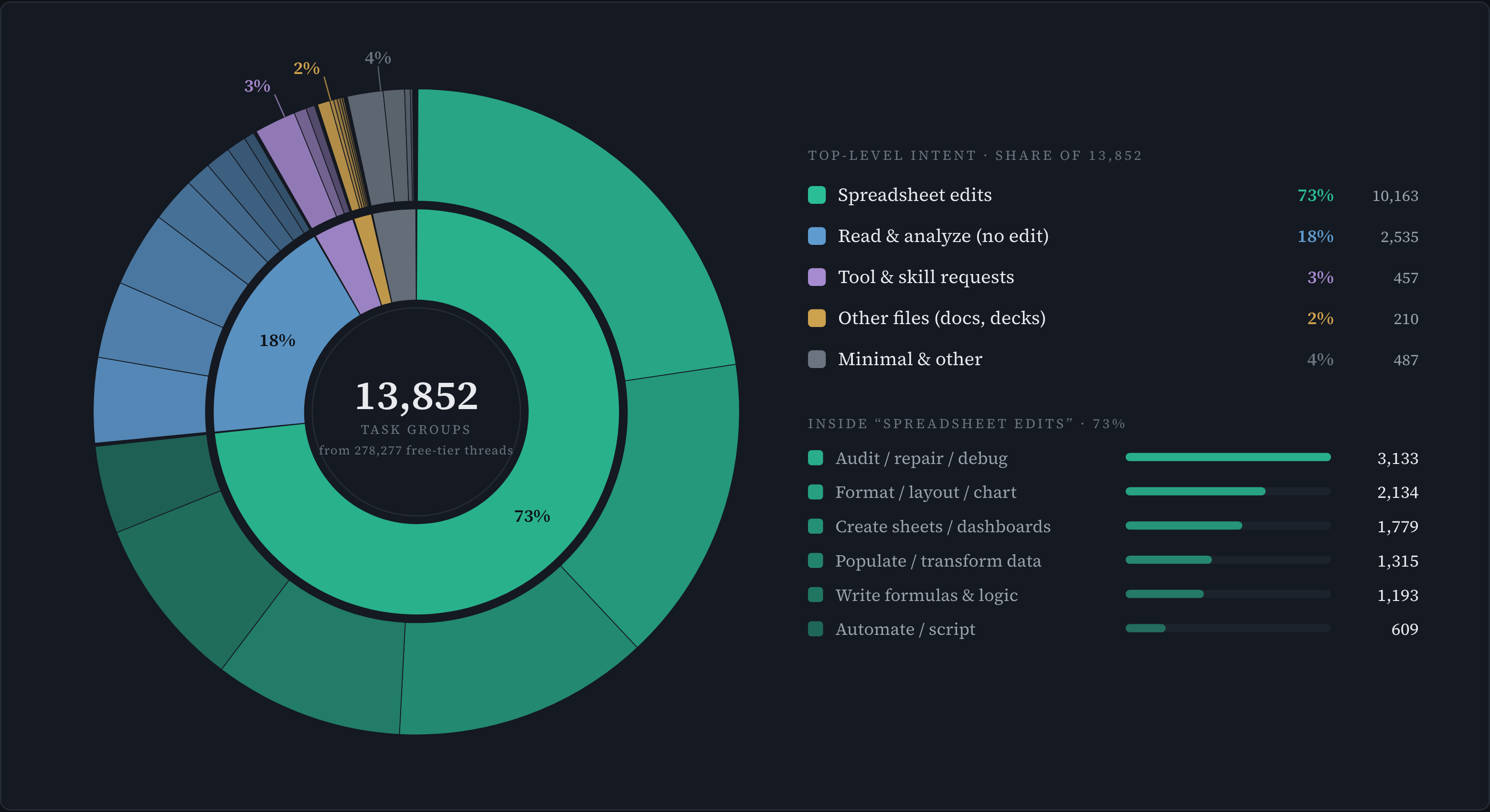
A taxonomy of real spreadsheet work
Built only from free-tier usage. Four top-level intents cover 99% of tasks — spreadsheet edits alone are 73%.
Dataset Construction
We organize production usage from free-tier users** into a taxonomy of spreadsheet work. We process ~300k agent trajectories into discrete tasks and sort these tasks into distinct kinds of work.
The top-level split is by the kind of spreadsheet operation. Four branches cover 99% of usage: writing values, formulas, or structure dominates at 73%, read-only analysis 18%, and the rest are non-spreadsheet work. Deeper levels then specialize by domain (financial modeling, data cleanup, pivot/summary tables, ...). Classifying tasks this way lets us generate synthetic tasks in distribution, keeping generated tasks grounded in real user needs.
Training Recipe
First, on-policy distillation (OPD): we train the model on GLM-5.1's feedback over the model's own outputs, using a cross-tokenizer loss. This raised performance from 44% to 53%. Second, RLVR (RL with Verifiable Rewards) with a GPT-5.5 agent judge, which pushed accuracy to 64.4%.
For each task, the judge is given the task's initial files and is instructed to first construct a task-specific checklist, like target cells, expected values or formulas, and areas that must not change before it sees any output from the student model. Committing to this scope upfront keeps the judge from being anchored by the student’s outputs. The judge’s rubrics weigh accuracy most heavily while factoring in secondary signals like formatting, style, and placement. The judge then scores all candidate workbooks in a batch against the rubric.
Open-sourcing
We will publish frequent and in-depth updates to Pivot as we refine our training recipes, improve our infrastructure, and train progressively larger base models. We have already published Mog, our production-grade spreadsheet environment for RL, which has substantially accelerated training by speeding up RL environment executions 20-30x against commercial spreadsheet engines. Next we will release our internal benchmark, ShortcutBench v1, a hard-verifiable set of in-distribution tasks that reflects spreadsheet workflows from our users and also gates the production release of Shortcut.ai.
Conclusion
Frontier-quality industry-specific models shouldn't require a frontier-sized lab. Pivot 0.5 is our first evidence that a small team can build top-performing models at low-cost by co-optimizing every layer of the stack.
To try Pivot for free in Shortcut.ai, click the research preview link and select Pivot.
Footnotes:
*Costs for all open-weight models are based on Fireworks.ai pricing. Pivot 0.5 and Qwen3.5 are served in-house via vLLM, but for standardization, prices are backfilled using OpenRouter prices for Qwen3.5 ($0.195/Mtok, output $1.56/Mtok; cached input = 10% of input rate)
**Only data from free-tier users without geolocation restrictions are included into our training data pipeline. Deterministic and LLM-based filters to exclude and redact sensitive content, including PII and NSFW content